
Flux Data Products
An Overview of Flux Data Products and Process Pipelines
Flux/Met data submitted to AmeriFlux are processed using the following pipeline to generate AmeriFlux BASE and AmeriFlux FLUXNET Data Products. See separate sections below for details of each step. Read a general overview of BASE and FLUXNET data products and processing in the following papers.
Chu, H., Christianson, D.S., Cheah, YW. et al. AmeriFlux BASE data pipeline to support network growth and data sharing. Sci Data 10, 614 (2023). https://doi.org/10.1038/s41597-023-02531-2
Pastorello, G., Trotta, C., Canfora, E. et al. The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data. Sci Data 7, 225 (2020). https://doi.org/10.1038/s41597-020-0534-3
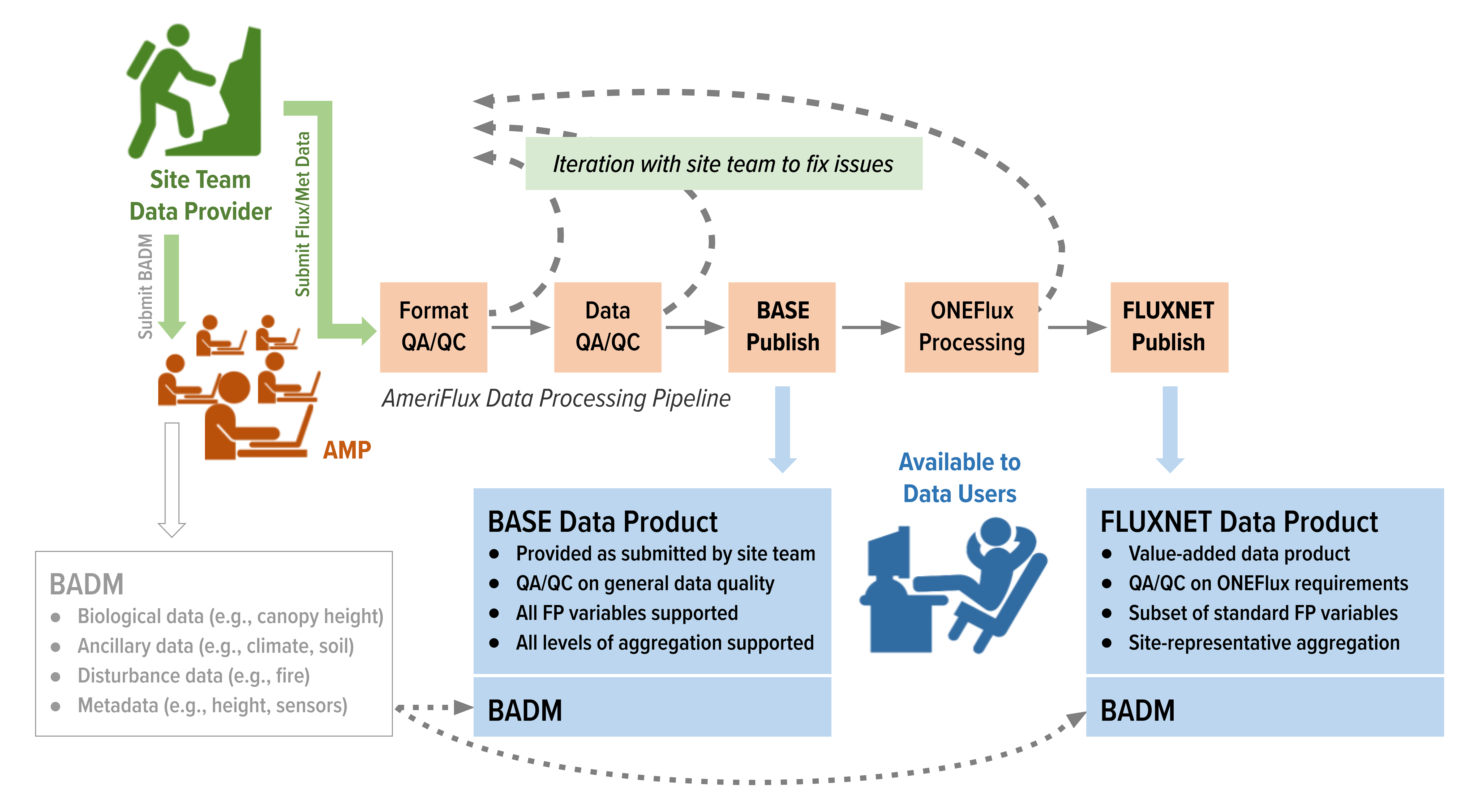
FP = Flux Processing and refers to the standard variable names, units, and file formats used in AmeriFlux flux/met data products.
BADM = Biological, Ancillary, Disturbance, and Metadata
Format QA/QC
The Format QA/QC step assesses compliance of flux-met data files uploaded to AmeriFlux with the required FP-In format. Format QA/QC is fully automated, and results are sent the same day. Format QA/QC can be an iterative process, especially if data files are being submitted for the first time.
Find more details at Format QA/QC and Format QA/QC Tests.
Data QA/QC
The Data QA/QC step assesses the data quality of a site’s entire record of flux/met data uploaded to AmeriFlux that has passed Format QA/QC. Data QA/QC can be an iterative process, especially for the first data submissions.
Find more details at Data QA/QC.
BASE Publish
In the BASE Publish step, AMP formats the submitted data in the FP Standard format, combines quality-checked flux-met data with BADM, provides or updates the BASE-BADM DOI, and makes the resulting BASE-BADM available to the AmeriFlux community via Download Data. Additional resources are available for site teams and other data users to use the published BASE-BADM.
Find more details at BASE Publish.
ONEFlux Processing
AMP applies the ONEFlux processing codes to generate the AmeriFlux FLUXNET data product for AmeriFlux sites. The FLUXNET product contains footprint-aggregated data that have been gap-filled and partitioned, and includes uncertainty analysis.
Find more details at ONEFlux Processing.
FLUXNET Publish
In the FLUXNET Publish step, AMP makes the AmeriFlux FLUXNET data product with BADM available via Download Data. BADM for sites with the AmeriFlux FLUXNET product can be optionally downloaded. AMP also provides or updates the FLUXNET DOI for each site. A beta version of the AmeriFlux FLUXNET data product is available.
Find more details at FLUXNET Publish.